Automated Website Uptime Monitoring with Workflow Automation
Overview
Modern digital operations depend on continuous availability of websites, APIs, and internal services. Few Good Geeks designed and implemented an automated website uptime monitoring system that replaces manual checks and opaque monitoring tools with a transparent, workflow-driven solution. For organizations managing complex data operations, our approach to Salesforce data import operations follows similar principles of automation reliability and transparency.
The system delivers continuous monitoring, real-time alerts, and historical logging while preserving full control over logic, data, and integrations.
The Operational Challenge
Many organizations rely on hosting alerts or occasional manual checks to monitor uptime. As systems grow, these approaches fail to scale and often detect outages too late.
- Downtime discovered by customers before internal teams
- No reliable historical uptime data or logs
- Alert noise without actionable context
- Limited visibility into monitoring logic and failures
Why Traditional Monitoring Tools Fall Short
Third-party uptime tools often operate as black boxes. While they send alerts, they limit customization, restrict integrations, and remove ownership of operational data.
Teams seeking reliability and transparency require monitoring that behaves like production infrastructure, not an external dependency.
The Workflow Automation Solution
Few Good Geeks implemented a self-hosted uptime monitoring workflow using n8n. The system executes on a fixed schedule and evaluates the health of websites, APIs, and internal services through observable, deterministic logic.
- Scheduled workflow triggers initiate monitoring cycles
- HTTP checks validate availability and response behavior
- Conditional logic detects failures or degraded states
- Alerts are sent immediately when downtime occurs
- Recovery notifications confirm service restoration
- Each execution is logged for historical analysis
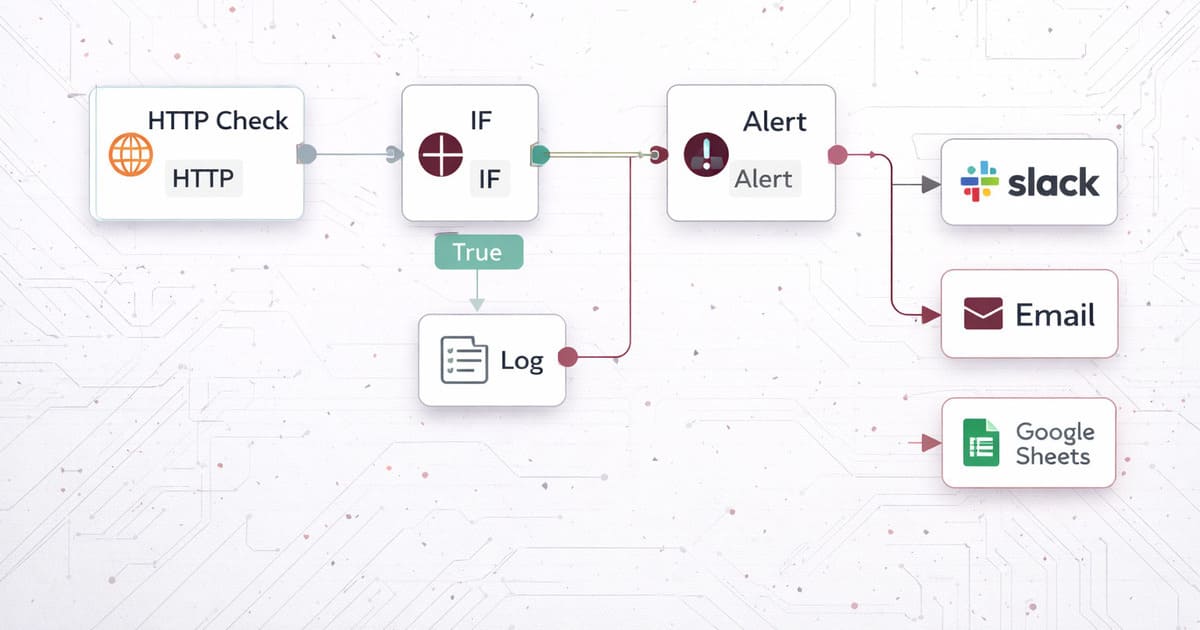
Alerting and Logging Strategy
When downtime is detected, the workflow sends real-time alerts through predefined channels such as email or Slack. Each alert contains service context, timestamp, and status details.
All checks are logged in a centralized system, creating a persistent operational record that supports SLA reporting, trend analysis, and root-cause investigations.
Business Impact
- Faster detection of outages without manual intervention
- Reduced mean time to response through instant alerts
- Verifiable uptime history for leadership and compliance
- Lower operational cost versus multiple SaaS tools
- Human time reclaimed from repetitive monitoring tasks
Conclusion
By treating uptime monitoring as a workflow automation problem, Few Good Geeks delivered a resilient, transparent system that scales with operational complexity. This same automation-first approach powers modern platforms like Salesforce Agentforce, where AI agents handle routine tasks while maintaining system reliability and transparency.
The result is continuous visibility, production reliability, and confidence that critical systems are monitored with the same discipline as the business depends on.
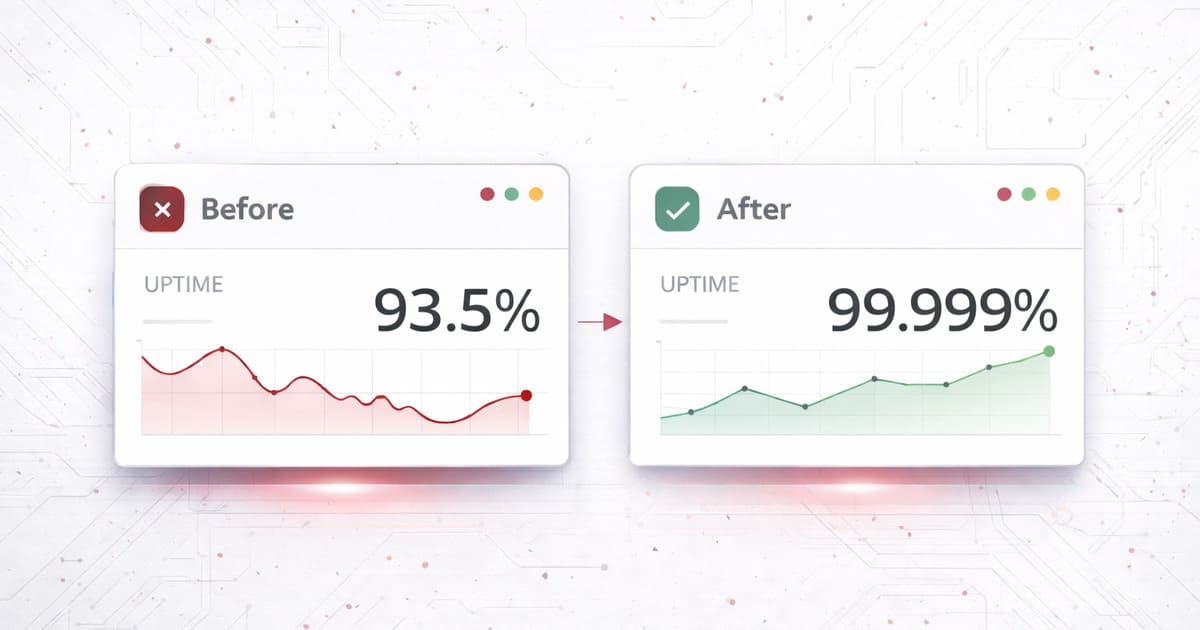
99.999%
Achieved uptime through automated monitoring
100%
Automated checks and alerts coverage
90
Less Manual uptime checks required